/
13 minutes read
The AI due diligence checklist: Vetting research tools for security & accuracy


Summary
Effective AI due diligence for research tools is critical for mitigating risks like hallucinations, data breaches, and bias, thereby ensuring research integrity. Vetting AI research platforms requires evaluating foundation model policies, platform-level engineering controls, continuous evaluation frameworks, and human-in-the-loop workflows. Key checks include confirming data isolation, multi-model architectures, bias benchmarks like BBQ, mandatory citations linking to source data, and human oversight for transcript and output verification. This rigor establishes trust, making insights accurate and reliable.
The qualitative research landscape is experiencing rapid growth, with new AI-powered platforms appearing weekly, each claiming to instantly summarise interviews or uncover research themes. This proliferation of tools presents a critical challenge for Research Operations (Research Ops) and insights leaders. The promise of increased efficiency is enticing, but the associated risks, particularly when vetting research tools for security, are considerable. These include the potential for AI hallucinations, data breaches, and the introduction of systematic bias, all of which necessitate careful evaluation.
We are currently seeing a paradox in modern research: teams are often drowning in data but starving for time. In the scramble to solve this so-called "Analysis Gap," many organizations are leaning on generic AI tools that are essentially "black boxes." They provide the "Wow" (the summary) but hide the "How" (the methodology). This year, more research will likely be produced, and trusted less, than at any other point in the history of the insights industry.
When a research agency or an in-house insights team adopts an AI tool, they aren't just buying software; they are staking their reputation on the accuracy of that tool’s output. This has led to a rise in "AI Due Diligence" as a critical enterprise capability. Organizations now require more than just a slick demo; they need an audit trail that proves the AI is a "bicycle for the mind" that amplifies human effort rather than a black box that replaces human steering.
What Does It Mean to Vet an AI research Tool for Security and Accuracy?
Vetting an AI research tool for security and accuracy means evaluating its foundation model policies, data privacy guarantees, bias benchmarks, engineering safeguards, evaluation framework, and human-in-the-loop controls to ensure research outputs are trustworthy, reproducible, and audit-ready.
Usually, when teams ask us for evidence of our standards, we provide our formal CoLoop Quality Control Document. But for those who are just beginning their vetting process, this post breaks down the four essential pillars of quality control you should demand from any research-grade AI platform.
Key Criteria for Vetting AI Tools
Accuracy and Reliability: Does the tool consistently produce correct, high-quality results? Test it with known, complex queries.
Transparency and Data Sources: Does the tool disclose its data sources? Avoid "black box" tools where the process of analysis is unknown.
Citation Verification: Verify if the AI-generated citations are real. AI can fabricate plausible-sounding, non-existent sources.
Privacy and Security: Check if the tool complies with data protection regulations (e.g., GDPR) and understand what happens to input data.
Bias and Equity: Evaluate whether the tool exhibits biases or provides equal accessibility.
Pillar 1: Foundation Model Safety and Data Sovereignty
The first step in any due diligence process is looking at the "engine" under the hood. Most AI research tools are built on top of Large Language Models (LLMs) provided by companies like Anthropic, OpenAI, or Google. However, simply using a powerful model isn't enough to ensure research-grade quality.
1. Multi-Model Architecture
A robust platform should not be locked into a single vendor. CoLoop maintains a multi-model architecture, allowing the system to select the best-performing and most appropriate model for each specific task. For example, Anthropic’s Claude is often the primary provider for complex content analysis and agent-based workflows due to its industry-leading focus on safety and alignment. Conversely, when vetting research tools for security you might prioritise different models for specific tasks. For instance, OpenAI models could be selected for translation, transcript correction, or quantitative analysis, while other providers are assessed for different needs. This multi-faceted approach to research tool selection ensures that if one platform experiences a quality decrease or service disruption, the integrity of your research, and therefore your security posture, remains protected.
2. The Training Taboo: Privacy and Fine-Tuning
The most critical question for an enterprise audit is: “Is my data being used to train your models?” For qualitative research, where PII (Personally Identifiable Information) and confidential business strategies are the norm, the answer must be a firm no. CoLoop ensures that customer content is processed solely to deliver the service and is never used to train, fine-tune, or improve any foundation AI model.
3. Bias Benchmarks and Mitigation
You should ask your vendor for specific, third-party bias benchmarks. For instance, are the models tested on the Bias Benchmark for Question Answering (BBQ)? This benchmark evaluates bias across social contexts to ensure the AI doesn't favor one demographic or viewpoint over another.
Anthropic (Claude): According to Anthropic’s published benchmark evaluations Claude Opus 4 achieved 0.21% bias with 99.8% accuracy on ambiguous questions, indicating minimal skew toward any particular group. Anthropic models undergo Constitutional AI training to ensure they remain helpful, harmless, and honest.
OpenAI (GPT): GPT-5 is described as OpenAI's least biased model to date. Studies across 66 tasks found that accuracy and hallucination rates were consistent across demographic groups, with harmful stereotype differences appearing in only ~0.1% of cases. Furthermore, GPT-5 underwent over 5,000 hours of red-team testing from 400+ external experts, achieving a ~30% reduction in political bias compared to GPT-4o.
Google (Gemini): Gemini models are evaluated against BBQ, WinoBias, and Winogender benchmarks, with results required to fall within strict safety thresholds before launch. Every model undergoes a four-stage safety evaluation, including manual red teaming by specialist teams.
Pillar 2: Platform-Level Engineering Controls
Generic AI tools are "black boxes", they take a prompt and provide an answer without showing the "math." A research-grade platform must implement engineering safeguards that constrain AI behavior to ensure factual grounding.
Transcription and Translation Integrity
Accuracy begins with the transcript. Due diligence should look for features like:
Confidence Scoring: Every transcribed word should carry a confidence score from 0 to 1. CoLoop highlights low-confidence words so researchers can manually review and correct them before analysis begins.
Keyword Correction: Researchers should be able to provide brand names, acronyms, and domain-specific terms upfront, up to 1,000 terms, to automatically correct common mistranscriptions.
Post-Processing: An AI-powered correction pass should identify and fix technical terms or acronyms, with each correction justified to the user.
Transcription Benchmarks: Vetting should include providers like AssemblyAI, which achieves a 93.3% Word Accuracy Rate, or Speechmatics, independently benchmarked as one of the lowest word-error-rate providers.
When it comes to global research, the gold standard is Native-Language Analysis. Transcripts should be analyzed in their original language before translation to minimize "meaning drift" and preserve the cultural nuance that is often lost in a direct English-only synthesis. For translation, DeepL is preferred as it is independently benchmarked as 1.3x-2.3x more preferred than competing services, maintaining a 94.0% match rate in technical peer-reviewed studies.
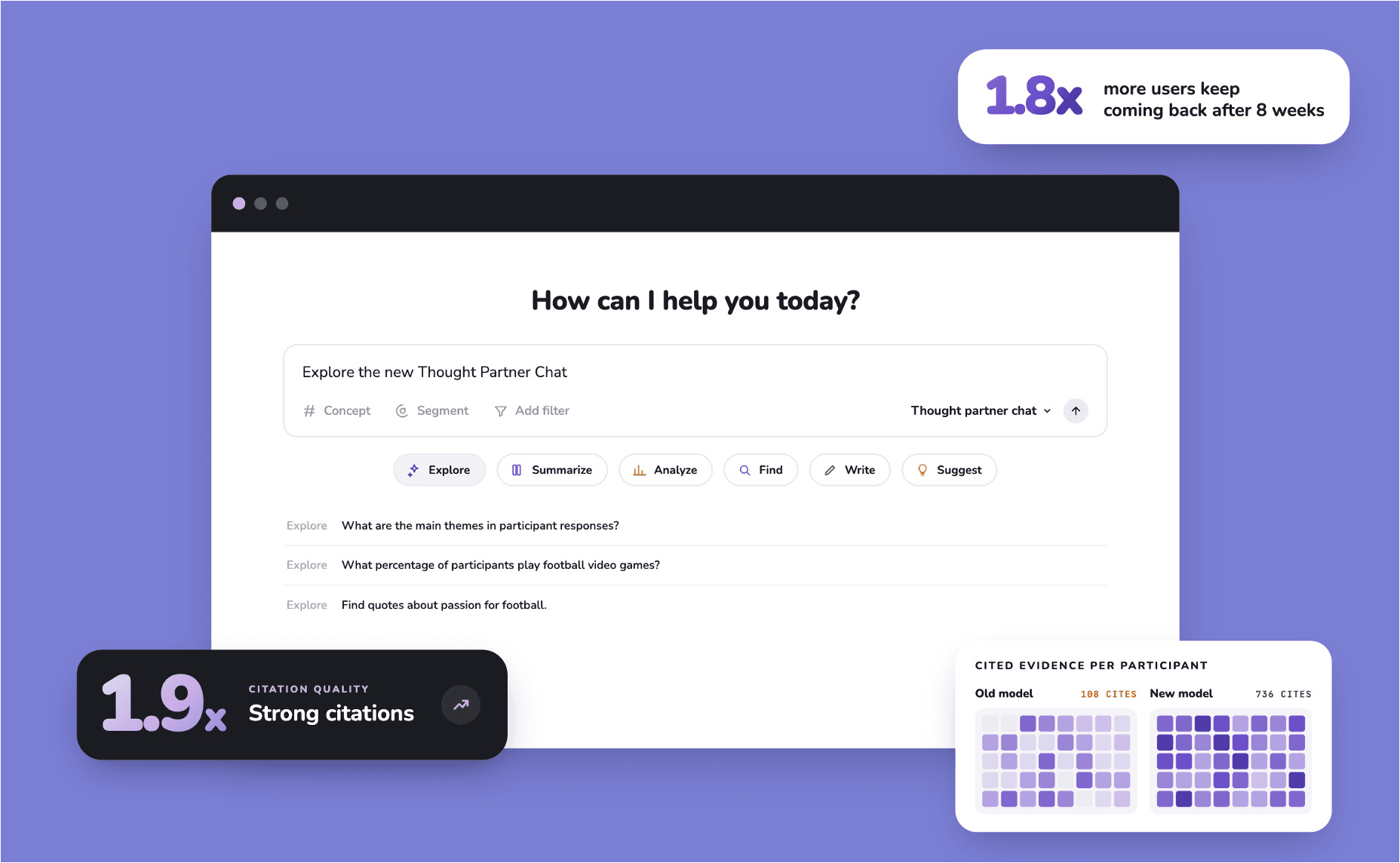
Mandatory Citations: The End of the Black Box
The most important platform control is Mandatory Citations. In a professional audit, an insight is only as good as the evidence behind it. Any tool used for qualitative analysis must link every claim, theme, or finding back to the original research data.
Citation Integrity: The system must enforce that citations are grounded in the original data and cannot be fabricated or modified by the AI. Reference IDs must be copied exactly from source data.
Evidence Panels: All analysis outputs, whether themes, summaries, or quotes, should link to a dedicated panel showing the exact supporting data, allowing researchers to click through to the source transcript or even a timestamped video moment.
Pillar 3: The Continuous Evaluation Framework
Quality control isn't a "one-and-done" checkbox. It requires constant monitoring and a systematic framework to ensure the AI remains accurate as models evolve.
Six Automated Evaluators
CoLoop maintains a framework where six dedicated automated evaluators run against AI outputs to monitor quality:
Hallucination: Are facts, claims, and quotes fully supported by the source data?
Relevance: Are the retrieved sources actually relevant to the researcher’s query?
Completeness: Does the answer include all key information from the sources, or has it "cherry-picked" data?
Helpfulness: Is the response concise, bias-free, and appropriately formatted?
Correctness: Does the answer match reference "ground truth" answers with proper attribution?
Consistency: Are there any contradictions across related question-answer pairs?
Benchmark Testing and Production Monitoring
Beyond automated checks, look for platforms that use frameworks like Braintrust for structured testing of specific tasks like quote extraction or speaker anonymization. Finally, a tool should incorporate Production Monitoring, where researchers can rate AI outputs (thumbs up/down) at the message, quote, or transcript level. This feedback loop informs ongoing quality improvement without using the data to train foundation models.
Pillar 4: Human-in-the-Loop Workflows
A critical part of any AI audit is understanding where the human fits in the process. AI should be a research assistant, not a replacement for the researcher. A research-grade tool must be designed to facilitate human oversight at every stage:
Speaker Assignment: Researchers should be able to review and correct automatic speaker detection to ensure only participant speech (not moderator speech) is used as evidence.
Transcript Review: Researchers must have the final say on the "ground truth" transcripts before analysis begins.
Prompt Guidance: The tool should explicitly remind researchers that the AI generates candidate answers, not final conclusions, and that every output must be cross-checked with the evidence panel.
Conclusion: Why Rigor is the New ROI
For years, the ROI of research was measured by speed and cost. But in the era of AI, those have become commodities. Today, we are filling organizations with "ultra-processed insights", reports that look good and scale fast but quietly damage decision-making.
The winning research teams of the next decade won’t be the fastest or the cheapest; they’ll be the most trusted at scale. Trust isn't just a byproduct of research; it is the product. In AI-assisted research, trust is established through enforceable citation integrity, bias testing, data isolation policies, and continuous quality monitoring. Whether you are a Research Ops manager conducting a vendor audit or a Lead Researcher trying to win over a skeptical stakeholder, the message is clear: AI is a powerful assistant, but only when it is governed by the same rigorous standards we apply to the rest of our craft.
By moving beyond the demo and into the data, organizations can finally embrace AI with the confidence that their insights are as accurate as they are fast.
The AI Due Diligence Checklist: Questions for Your Vendor
To help you get started, here is a summary checklist of questions to ask any prospective AI research tool vendor:
Pillar | Question |
|---|---|
Foundation Models | Do you use a multi-model architecture for resilience? |
Is our data used to train or fine-tune any AI models? | |
Can you provide BBQ bias benchmark results for your models? | |
Platform Controls | Does the system provide confidence scoring (0-1) for transcripts? |
Can we provide up to 1,000 custom keywords to boost transcription accuracy? | |
Is analysis performed in the native language or via English translation? | |
Does the system mandate citations that link directly to verbatim transcripts? | |
Evaluation | Do you run automated evaluators for hallucinations and relevance? |
Do you have a "Human-in-the-Loop" workflow for speaker and transcript correction? | |
Is there an evidence panel for researchers to verify AI outputs? |
Is your team ready to scale trust and quality? CoLoop is currently trusted by teams at Amazon, P&G, Nike, and Netflix to make their most important decisions.