Product Updates
/
4 minutes read
Building Chat 2.0


Summary
Building Chat 2.0 by CoLoop significantly improved qualitative data analysis by addressing key user needs. Research involving 132 customers and 1,118 chat prompts revealed 55.8% of queries needed specialized handling due to limitations in trust, simplicity, and scalability. CoLoop identified 9 query types and 6 main user challenges, prominently data coverage (29.56%) and low reliability (18.87%). The new Chat 2.0, grounded in specialization, simplicity, and reliability, yielded a 61% user improvement across five critical dimensions.
TL;DR
We spoke to and surveyed 132 customers of CoLoop along with 1,118 chat prompts from the last 6 months to understand how to build the best analysis tool tool for qualitative data.
We identified 9 key types of queries and determined 55.8% of total prompts run could be significantly improved with specialised handling for these queries.
This led to the establishment of 5 measurable pillars for driving quantitative improvement in our analysis tooling.
We used these insights to develop, launch and measure the impact of “Chat 2.0” with 61% of users reporting an improvement across our 5 key dimensions.
“When you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind: it may be the beginning of knowledge, but you have scarcely, in your thoughts, advanced to the stage of science, whatever the matter may be.”
— Lord Kelvin
Figuring out what to focus on
Before setting out to build Chat 2.0 we conducted user research to better understand where the opportunities were in our current offering. We conducted deep analysis of usage patterns and collated information from hours of support and feedback calls.
Through this process we identified several key limitations that were compromising trust and holding back some researchers from experiencing further efficiency improvements:
1. Trust & completeness. Researchers asked for dependable citations and numeric counts. Even small errors forced manual fact‑checks and hand tallies.
2. Simplicity. When to use grids versus chat, and how segment/concept tagging works, was unclear—leading to unsatisfiable or misinterpreted prompts.
3. Scalability & flexibility. Teams wanted deep qualitative analysis on larger datasets without choosing between lower‑coverage chat answers and rigid grid outputs. They also wanted tooling that could scale as rapidly as their sample sizes.
To deepen our understanding, we collected additional data to answer two questions:
1. What are people trying to do with CoLoop?
2. Where does the experience fall short most often?
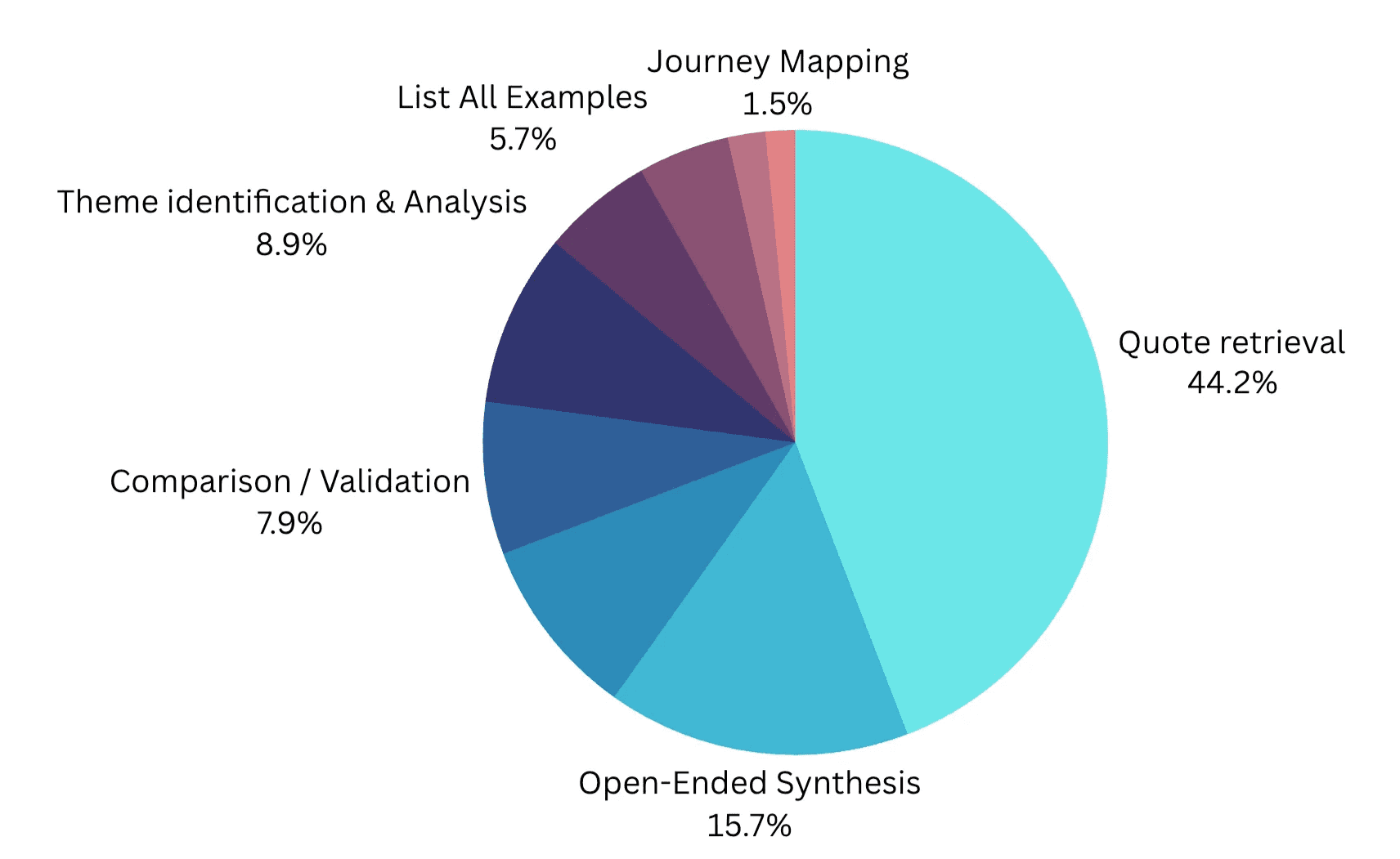
Most common queries in CoLoop Chat
We analysed 1,118 prompts from the last 6 months. We developed a nine-category intent taxonomy bottom up using the CoLoop open ends tool. From this we found that in as many as 55.8% of cases users were likely resorting to generating their required analysis through a mixture of multiple prompts, grid + chat questions as well as use of 3rd party LLMs like CoPilot.
What are your 3 main limitations with the CoLoop Chat right now?
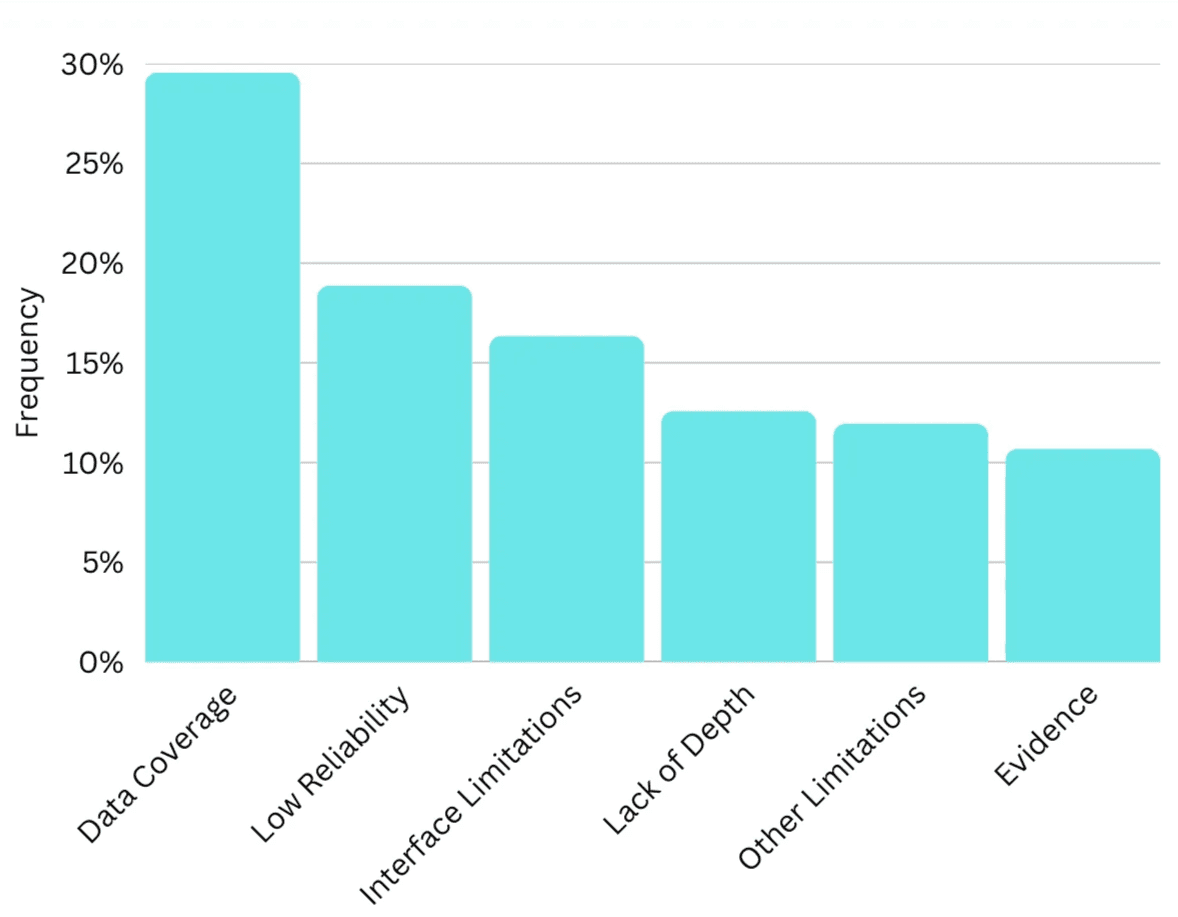
Next we next asked 30 Participants to outline their top 3 challenges with CoLoop. Using the CoLoop open ends tool we coded their responses into 6 main categories.
Category | Description | Share of mentions |
|---|---|---|
Data coverage | Incomplete Data Coverage & Limited Evidence Sourcing | 29.56% |
Low reliability | Irrelevant quotes or incorrect counts are shown alongside outputs. | 18.87% |
Interface limitations | Confusion around how and when to use specific features like analysis grids, chats, segments etc. | 16.35% |
Lack of depth | Lack of Depth, Detail, and Analytical Rigour | 12.58% |
Evidence | Shows wrong or irrelevant evidence | 10.69% |
Other | Other reasons not listed above | 11.95% |
Paving the way to Chat 2.0
Based on the data we gathered way to deliver on our initial qualitative phase became clearer:
Specialisation: Purpose‑built flows for the most common jobs (e.g., quote extraction with exact source spans, numeric aggregation with unit awareness, theme synthesis with coverage reports), instead of forcing everything into generic chat or rigid grids.
Simplicity: The system routes queries automatically: intent detection → feasibility check → tool selection → answer contract. Users shouldn’t need to understand segment tagging or other nuances of prompting to get the right result.
Reliable: Above all we had to improve reliability. Citations needed to be perfect. Any question the chat agreed to answer needed to be answered properly or rejected.