Product Updates
/
5 minutes read
Building Chat 2.0 Part 2: Beta Testing

Summary
CoLoop surveyed 132 customers and analyzed 1,118 chat prompts to identify gaps in its qualitative analysis tool. The research revealed 9 key query types with 60% of prompts requiring specialized handling. CoLoop built Chat 2.0 with five dedicated analysis tools: quantitative questions for yes/no tallies, flexible quote finding with precise specifications, thematic analysis for data coverage, concept testing with sentiment breakdowns, and enhanced evidence displays.
TL;DR
We spoke to and surveyed 132 customers of CoLoop along with 1,118 chat prompts from the last 6 months to understand how to build the best analysis tool tool for qualitative data.
We identified 9 key types of queries and determined 60% of total prompts run could be significantly improved with specialised handling for these queries.
This led to the establishment of 5 measurable pillars for driving quantitative improvement in our analysis tooling.
We used these insights to develop, launch and measure the impact of “Chat 2.0” with 61% of users reporting an improvement across our 5 key dimensions.
Designing Chat 2.0
In the last article we outlined how our user research demonstrated the need for a tool with deep specialisation towards expected prompts, reliable performance and simple use. With Chat 2.0 we set out to address this in the following ways
Analysis Tools
Using the list of prompts we identified in the first part of our analysis we built out specifically tooling to address the key user intents. Each of these tools was designed to cover the core use cases we’d seen emerge from our previous analysis of usage:
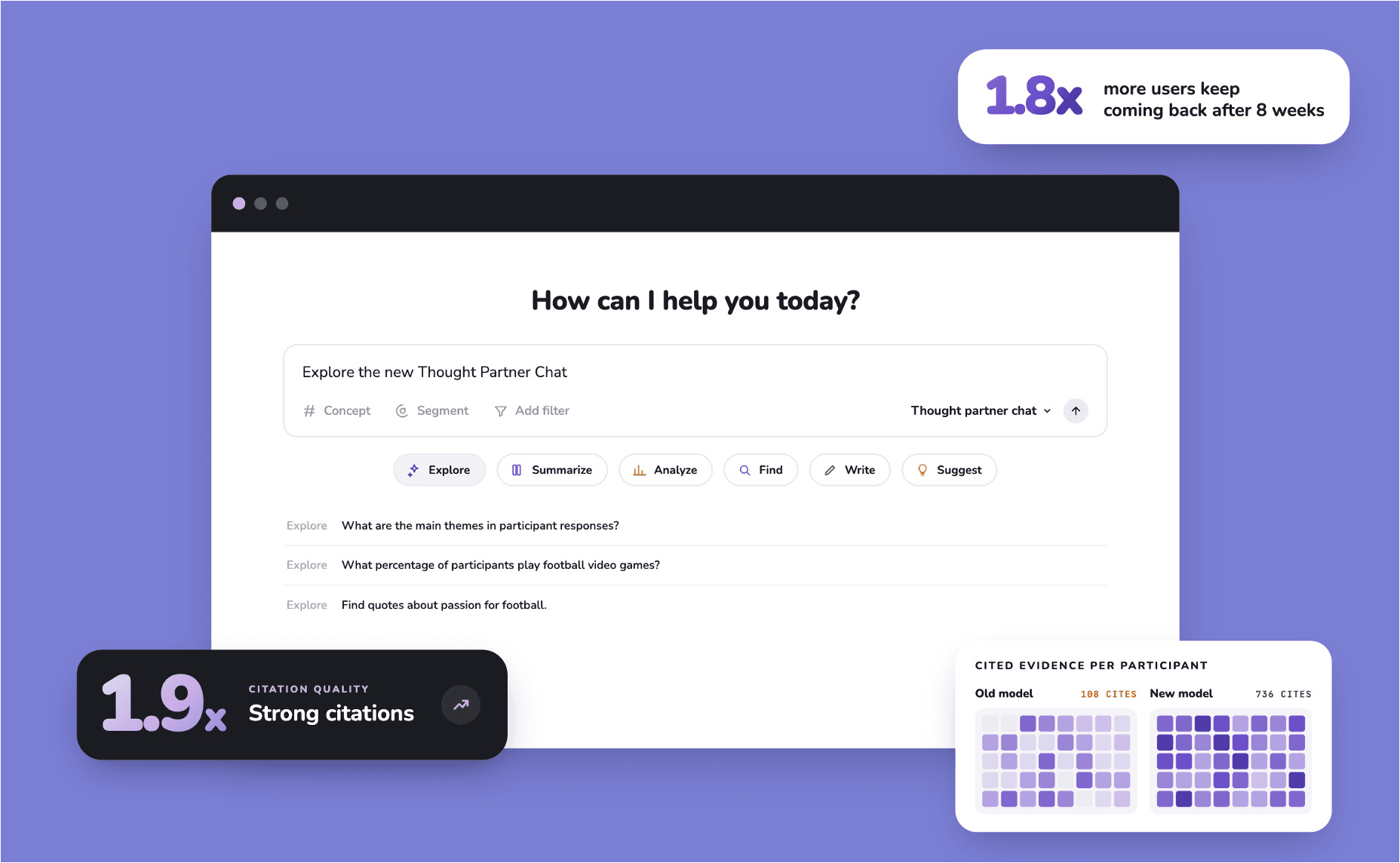
1. Quant Questions
Chat 2.0 has been fantastic! It is great to have this level of analysis and quantification - Sequentis Health
Using this tool the AI chat will tabulate result from every single participant in response to a simple or complex yes or no question. Using this tool you can now tally responses to complex questions like “How many participants sounded doubtful?”.
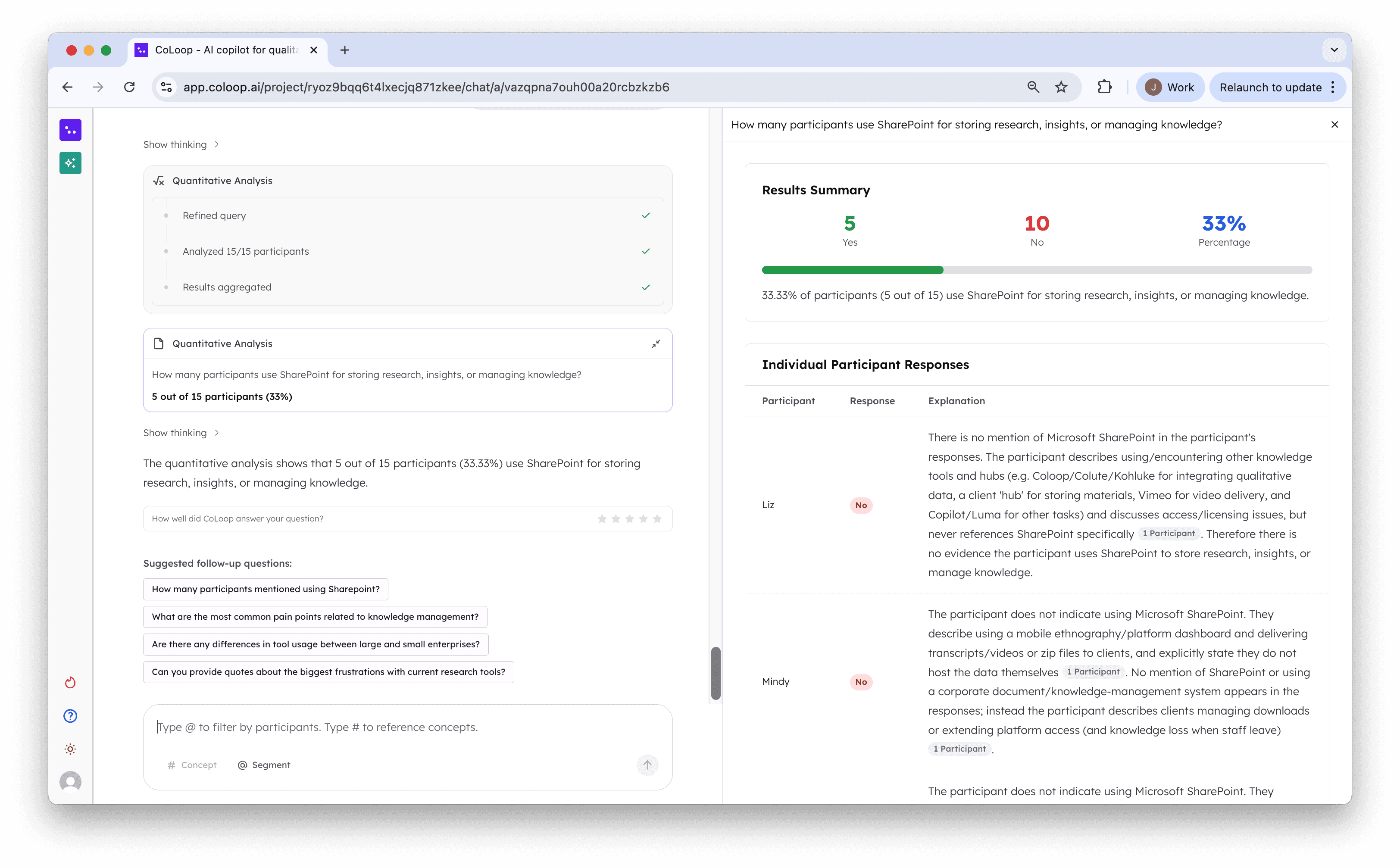
2. Quote Finding
This was a core use case in Chat 1.0 however from our user interviews we found researchers didn’t find enough variety and flexibility in the quotes they were able to source. Finding the top 10 responses was easy but more complex queries like “Find one quote from each segment” or “Find 2 quotes for each participant” weren’t possible. Until now. This enables researchers to quickly and accurate source evidence to their direct specification.
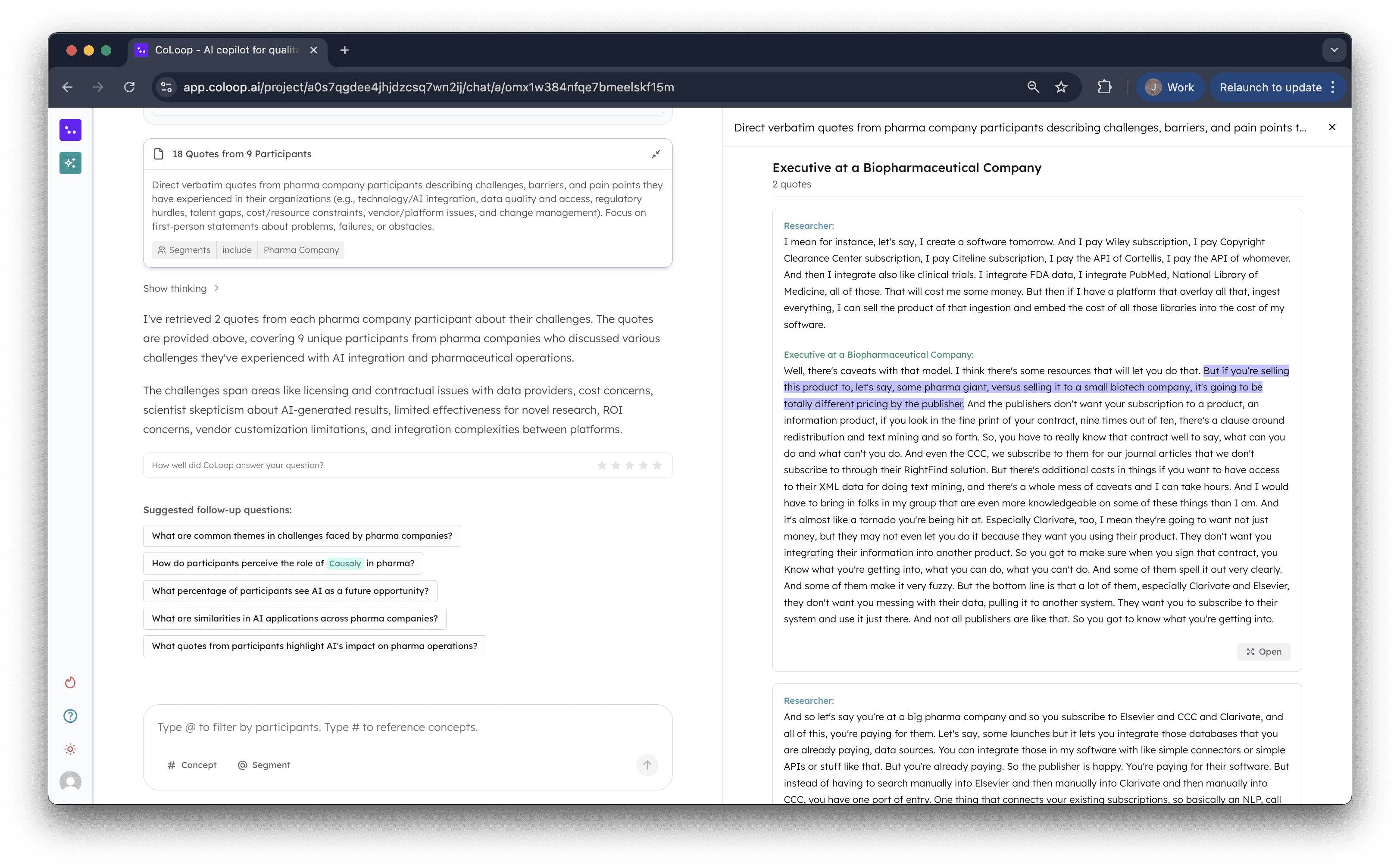
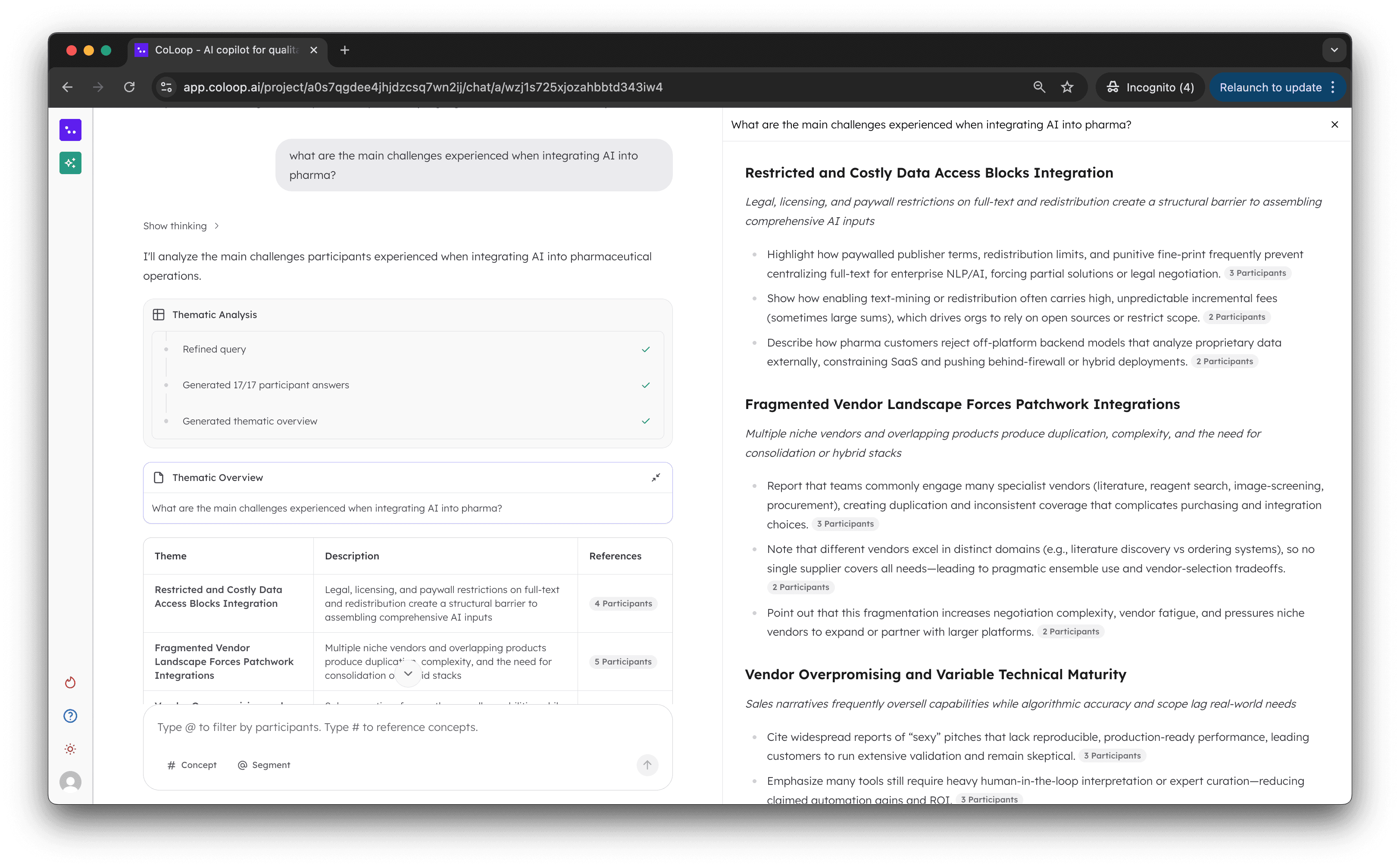
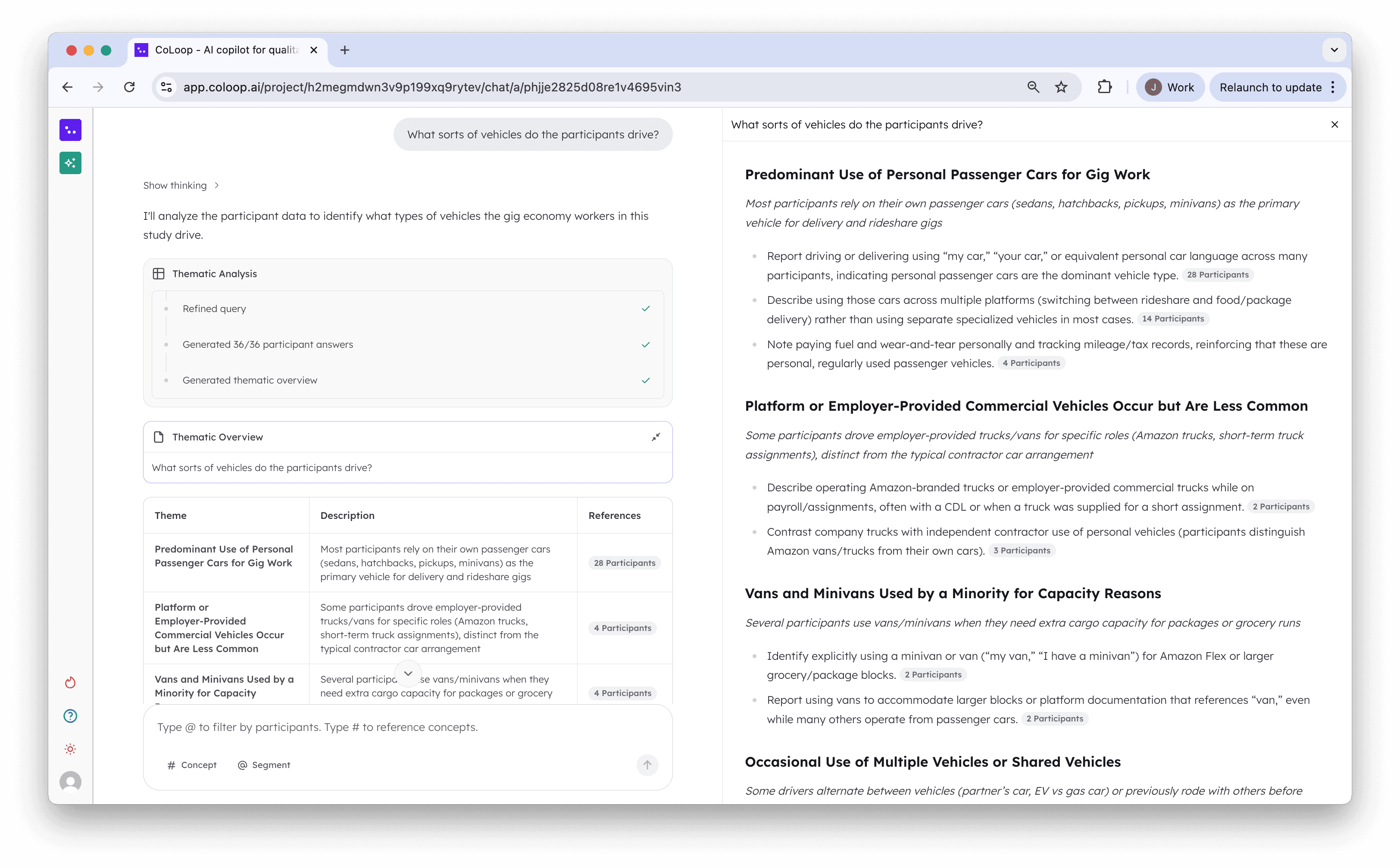
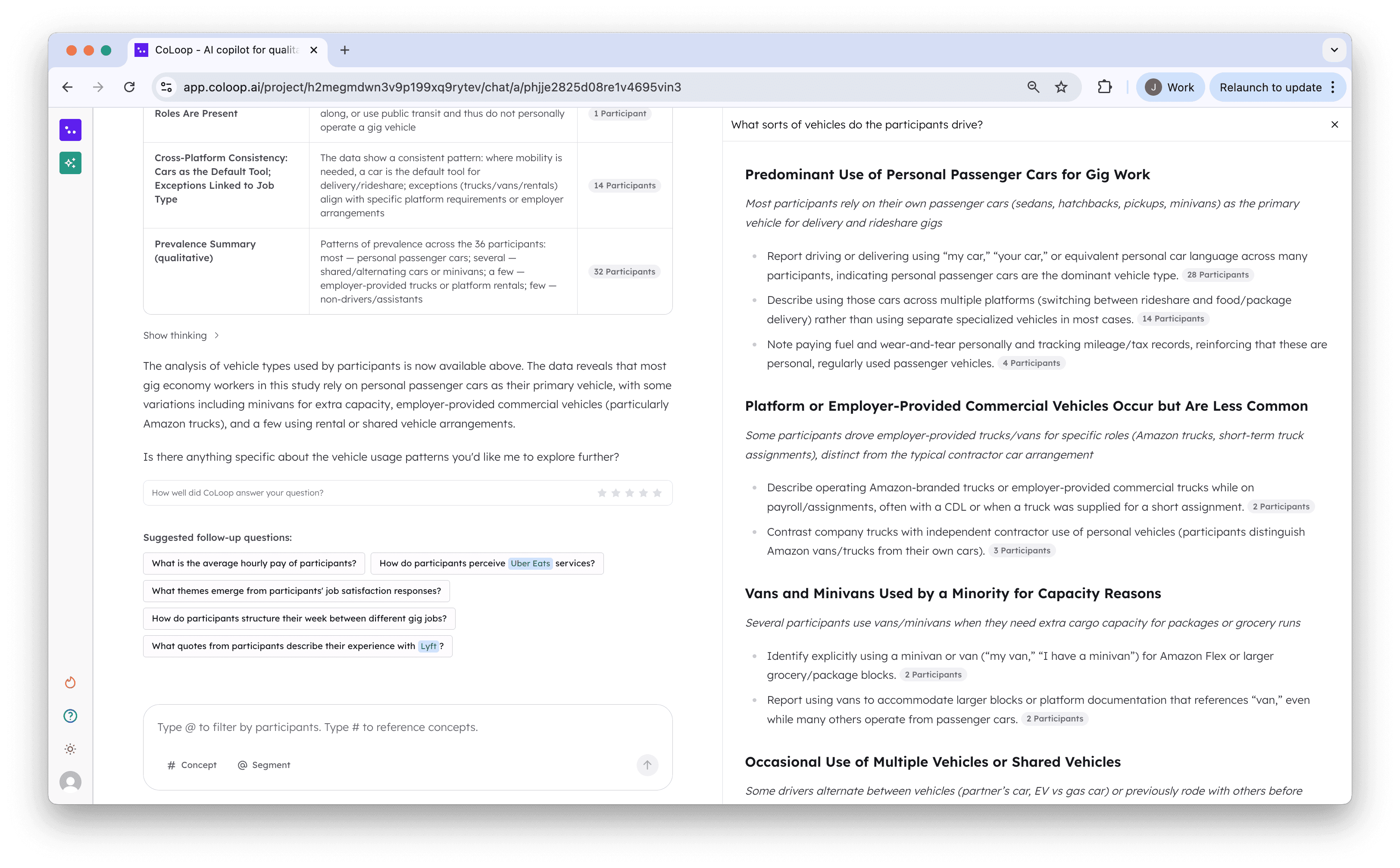
3. Thematic Analysis
Data coverage stood out as a key area for improvement in Chat 1.0. Particularly as CoLoop scaled to larger teams we often saw teams reaching for the AI chat first. We originally build the analysis grid to handle these types of queries however
Used to do this in the grid
Can now do this in the AI chat
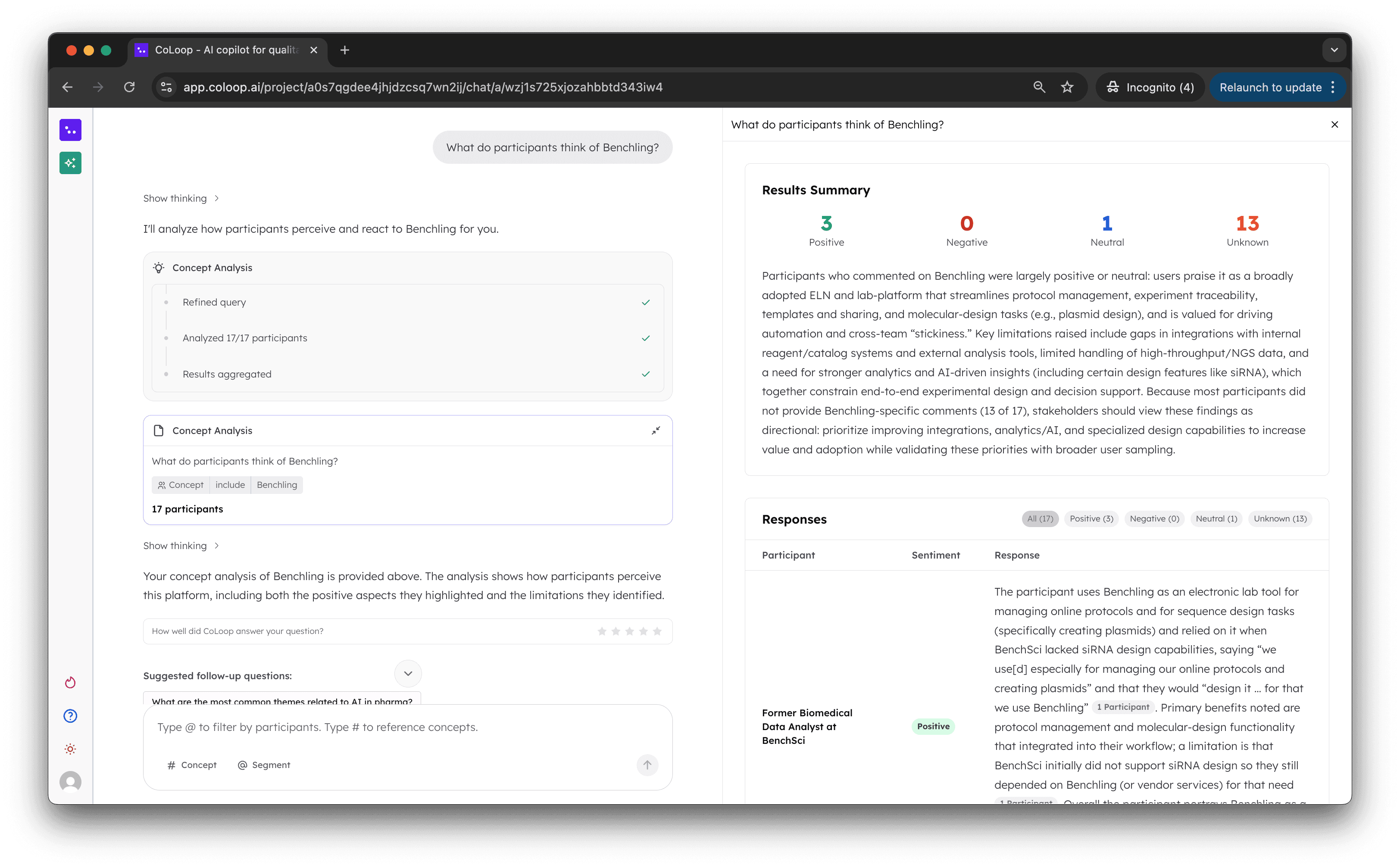
4. Concept Testing
Now show the concept along with a sentiment breakdown of how users perceived the concept
Reduces researcher time spent flipping back and fourth between multiple different concepts or messages
Introduced Artefacts + Summaries
Fabulous improvement! The accuracy of the outputs and the ability to generate visual representations of the findings is game-changing for Co-loop use, it has saved me hours in analysis and reporting. - Savanta
Every analysis tool generates a detailed outline on the right hand side containing fully cited links and themes.
The results of these are further summarised into a shorter bitesize output in the chat
Both are linked back to supporting evidence giving the user the flexibility to both see a quick answer at a glance or deep dive into further detail in a progressive and uncluttered interface.
Contextual Suggestions & Feedback
Please bring it online soon for full use! :) - Radius Group
At the end of every chat messages we’ve also now included suggested follow up questions and feedback. After being inspired by this excellent Built for Mars case study we decided to incorporate suggested questions. These suggestions whether clicked or not enable us to subtle guide researchers to uncover more and more functionality as they go thereby reducing the burden of running training sessions while maintaining feature adoption.
On top of this we’ve raised the prominence of feedback features to drive further continued improvement in this new development phase of CoLoop.
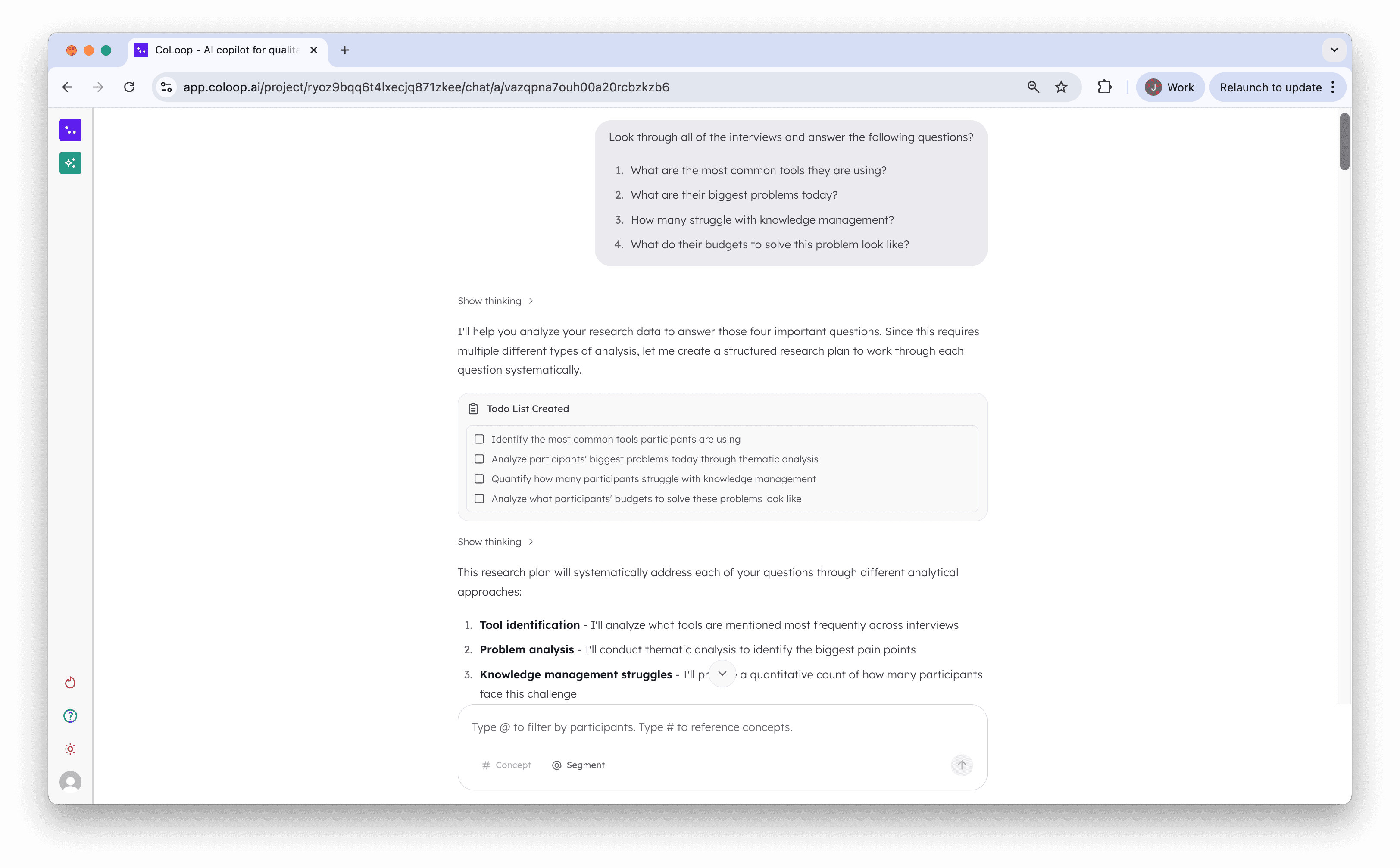
Multiple Queries at once
Added planning and enabled users to run multiple queries at once
In some cases users
How well does Chat 2.0 address previous limitations of the old Chat?
It is like having a supercharged team member on your side! - The Research Heads
Based on the 5 dimensions we identified in the first part of our research we created a follow up matrix question to determine the effects of the 2.0 improvements. Overall across all dimensions 61% of users reported improvement across our 5 dimensions.
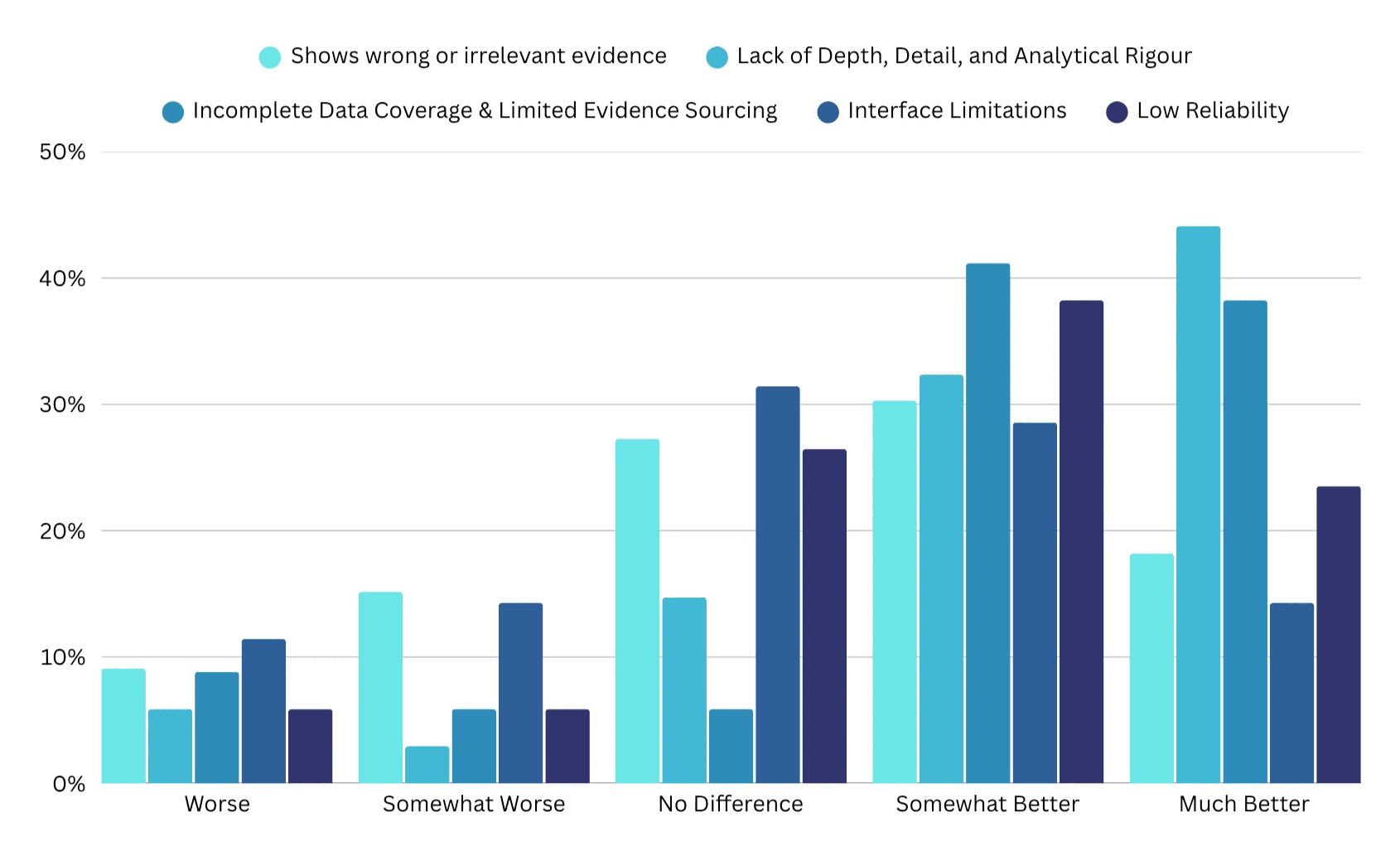
Evidence | Lack of Depth | Data Coverage | Interface Limitations | Low Reliability | |
|---|---|---|---|---|---|
Worse | 9.09% | 5.88% | 8.82% | 11.43% | 5.88% |
Somewhat Worse | 15.15% | 2.94% | 5.88% | 14.29% | 5.88% |
No Difference | 27.27% | 14.71% | 5.88% | 31.43% | 26.47% |
Somewhat Better | 30.30% | 32.35% | 41.18% | 28.57% | 38.24% |
Much Better | 18.18% | 44.12% | 38.24% | 14.29% | 23.53% |
How were people using the chat before vs. after?
We reran the analysis of chat prompts on a small sample of 70 beta testers. From these results we noted a much greater diversity in the range of prompt intents. A ~50% reduction in other category queries and simple quote retrieval signals clearer user intents and a greater alignment with decision making and analytical use cases rather than just quote finding for decks.
Type of query | Before | After |
|---|---|---|
Quote retrieval | 46.15% | 21.60% ⬇️ |
Theme identification & Analysis | 9.35% | 33.30% ⬆️ |
Quantitative Analysis | 4.95% | 20.70% ⬆️ |
Comparison / Validation | 8.25% | 9% ⬆️ |
Other | 31.30% | 15.40% ⬇️ |
Improving accuracy and raising researchers’ confidence in CoLoop
Improvements to the way we generate citations and display evidence have generated and considerable upswing in perceived confidence of CoLoop. Users self reported confidence in outputs from CoLoop increased by up to 14% on average as compared to the same question asked for Chat 1.0. In this latest iteration citations are not only considerably faster but also even more accurate.
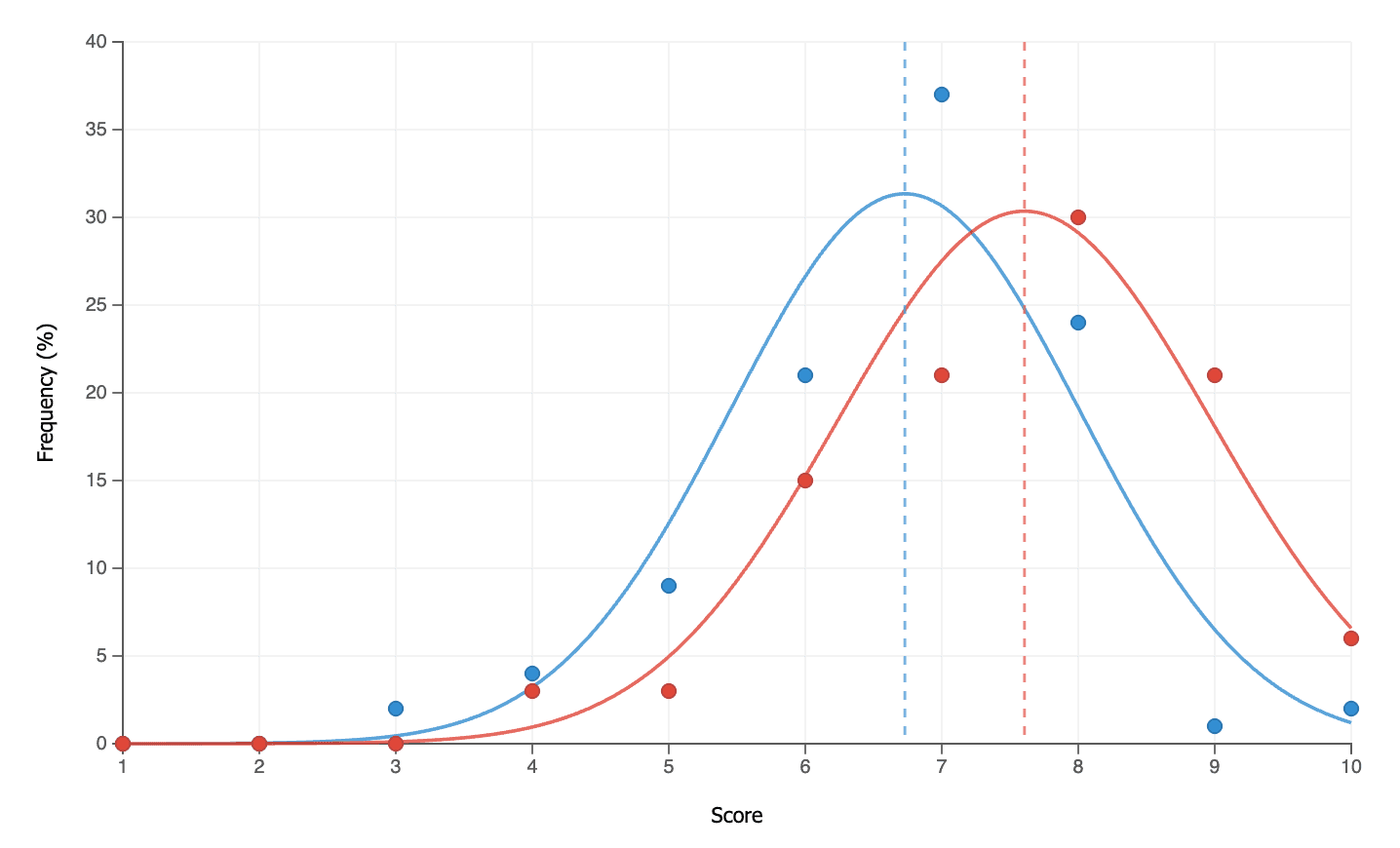
Before | After | |
|---|---|---|
Mean Score | 6.72 | 7.61 (+13.2%) |
Median Score | 7 | 8 (+14.3%) |
What’s Next …?
Transcription Quality
Concept Detection
Scale
Up next we’re looking to hear from you. Chat 2.0 is now generally available in beta for our paying subscribers and we’d love to hear what you make of it. If yo