Product Updates
/
3 minutes read
Introducing the new Thought Partner Chat, rebuilt for verifiable analysis

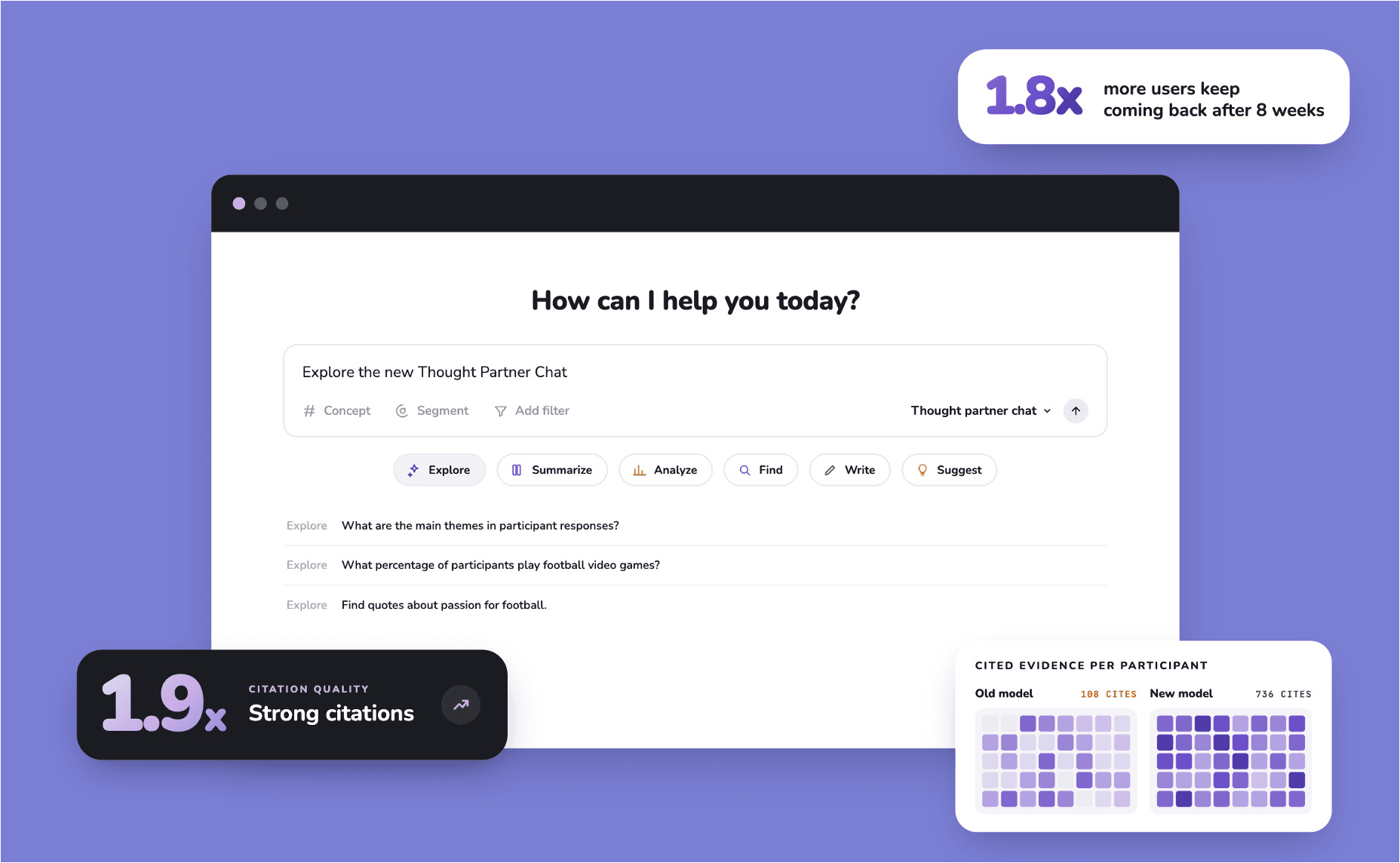
Summary
AI tools have made qualitative analysis faster, but not necessarily more trustworthy. Researchers still spend hours manually validating quotes, prevalence claims, and participant scoping because generic AI tools often hallucinate evidence or flatten nuance. CoLoop's thought partner analysis is changing this.
AI has made it dramatically easier to generate insights from data, and dramatically harder to trust them. For researchers, AI generated analysis can feel like a black box: Did the model read your data, or just part of it? Is the quote real? When it says "most participants," does it mean most, or two? For researchers whose work has to hold up under scrutiny, that uncertainty is hard to live with. As one researcher who recently switched from Claude Code to CoLoop put it: "Right at the end I discovered Claude had only ever been looking at ~15% of my research data.”
So researchers check. They go back to transcripts for quotes, count prevalence by hand, verify scoping. Generic AI offers no efficient way to do that, so the time saved on the front end is spent on the back end.
CoLoop's Thought Partner Chat (previously Chat 2.1) was purpose-built to close that gap. Outputs are designed to be easy to verify, held to a higher bar for rigour, so the time saved on generation isn't lost to validation.
It was built for qualitative researchers, by qualitative researchers. To rebuild it, we surveyed 200+ researchers, then spent a month on-site with the most rigorous researchers across the US, UK, and EU, from Research Associate to Director. The programme ran in four stages:
Discovery interviews,
Observational sessions on live projects,
Conversations with the non-researchers who rely on their work,
Focus groups to consolidate priorities.
This blog covers what we learnt and what we built.
What we heard: 4 things researchers need from qual AI
We rebuilt the chat with researchers. They told us what they need from qualitative AI, consistently. Here's what we heard:
1. Reliable outputs that reflect what participants actually said
Hallucination and factual errors are the most trust-destroying category of failure. Two patterns show up:
Fabrication: A 2025 study on Microsoft Copilot found 58% of the participant quotes the tool generated to support its themes were fabricated. Quotes that looked real, attributed to real participants, but absent from the data.
Inflated frequency language: Models stretch frequency language, calling a finding "the majority view" when only a handful of participants raised it. This breaks trust because quantifiers are the levers researchers use to signal how strong a finding is.
2. Evidence that defends every insight
Evidence is what turns an output into something researchers can defend and review. Without it, an analysis sits in a black box, directionally plausible, but difficult to verify.
Citation accuracy: AI can over-interpret raw data, and when researchers check the citations, they don't always align with the point they're attached to.
Dataset representation: Relevant verbatims get missed, or pulled disproportionately from a small subset of participants, skewing what the analysis appears to represent.
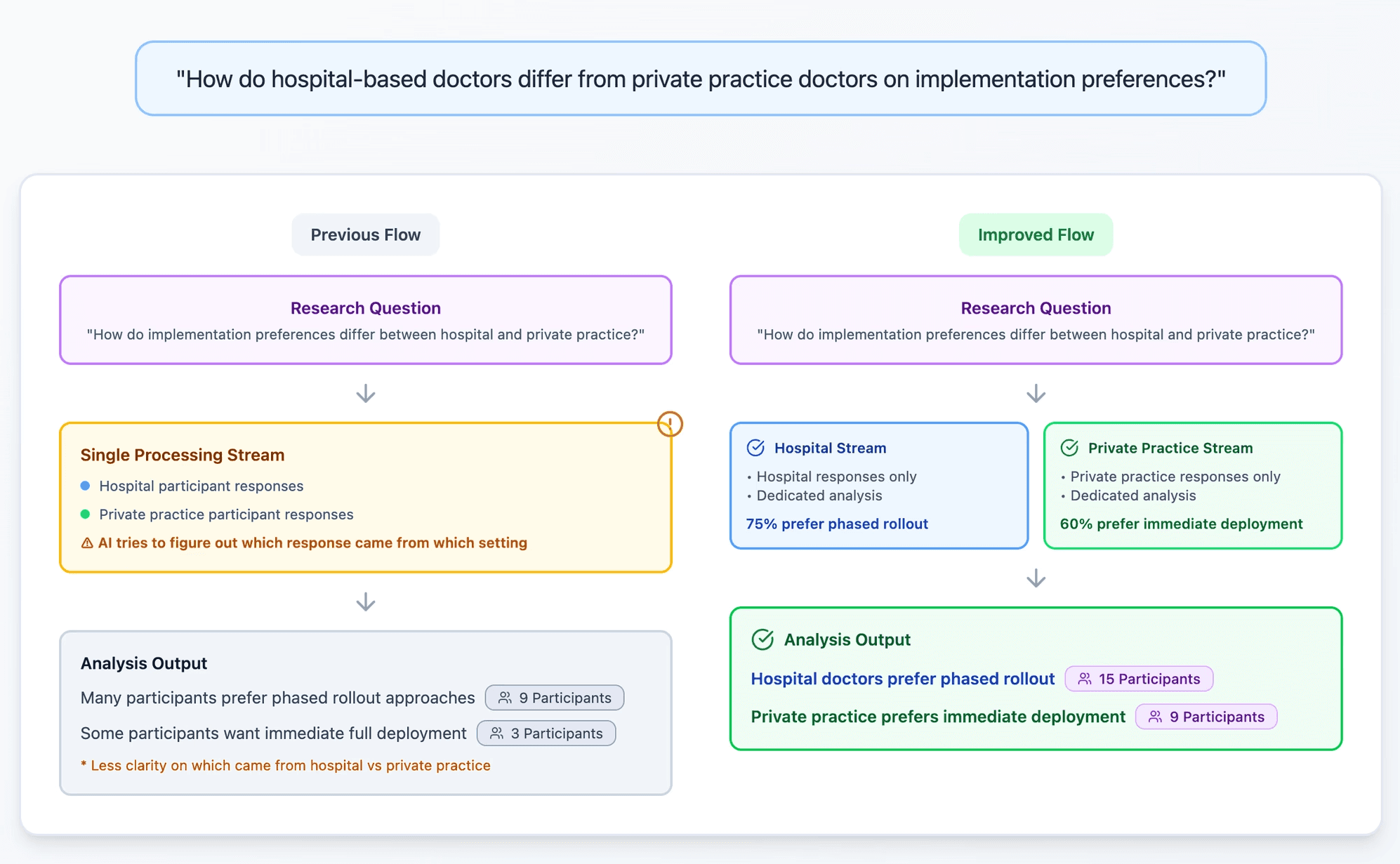
3. Analysis bounded by the data researchers scoped
An analysis is only as accurate as the data feeding it. This matters most when researchers narrow the scope to a specific group of participants or a specific section of each transcript.
Transcript section: When researchers ask about responses to a specific part of the discussion guide, or compare spontaneous and prompted responses (pre- and post-stimulus), the analysis should stay anchored to that section, not surfacing unrelated moments where a trigger word happens to appear.
Participant segments: When researchers compare groups, the filters they set need to hold. Quotes should be attributed to the right segment, and filters should never be quietly ignored.
4. Depth that preserves the detail
When AI synthesises, nuanced findings often collapse into generic outputs. Contradictions, minority perspectives, and contextual detail get flattened or overlooked, leaving outputs too surface-level to put into a report.
Nuance: Tension and disagreement across participants, exactly the signal qual research exists to surface, gets averaged out of the summary.
Minority perspectives: The quieter voices in the dataset disappear into the headline finding, even when they're the more interesting story.
When AI gets these wrong, the failures compound across the team. Junior researchers, without deep domain expertise, mistake the coherence and volume of AI outputs for quality. Seniors can't tell whether a colleague's slide came from transcripts or the model: "I don't think we're confident in each other and we don't know what the other person has done when they produce the slide." So they redo the analysis by hand, "adding a lot of hours to analysis."
What we changed in the new Thought Partner Chat
Today we're launching the new Thought Partner Chat, CoLoop's most-used analytical surface for qualitative research. Researchers set the direction; months of engineering turned each need into a product change. Here's what's different.
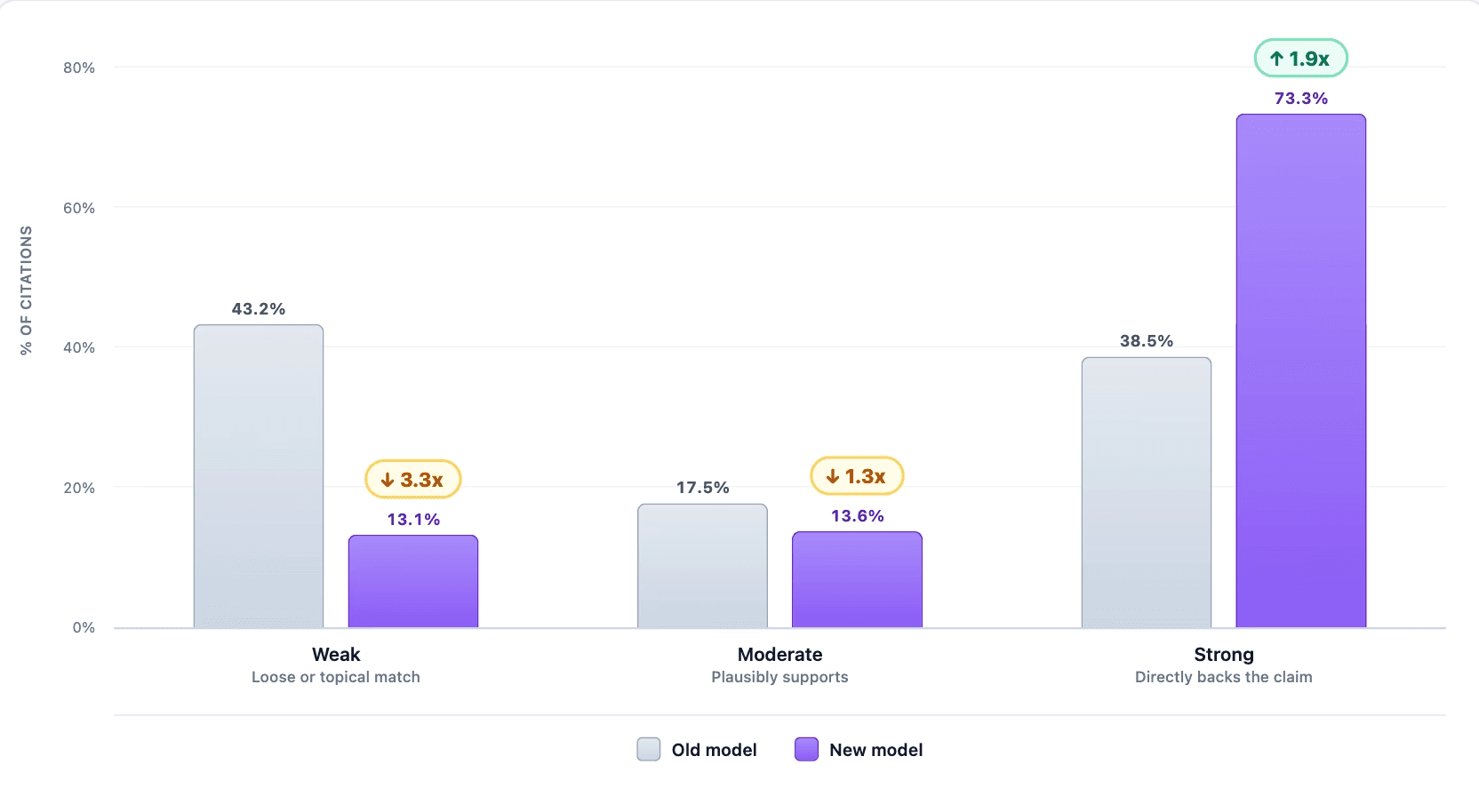
1. Relevant and accurate citations
Across hundreds of citation-quality evals, the share of strong citations rose 1.9x. The share of moderate citations (citations that are contextual, inferential, or that support part of the claim) is 1.3x less. Weak citations, the kind that used to send researchers back to the transcript to figure out what the model was thinking, fell 3.3x.
“I spent a lot of time using the thought partner feature in the chat, happy to share that the quote has been very accurate, rarely needed to go check a transcript for something I heard but wasn’t seeing pulled up. Appreciate the time it took your team to develop this!”
2. Representative evidence
The Thought Partner Chat reads across your full dataset on every query and citations distribute across the participant pool rather than over-indexing on a few loud voices.
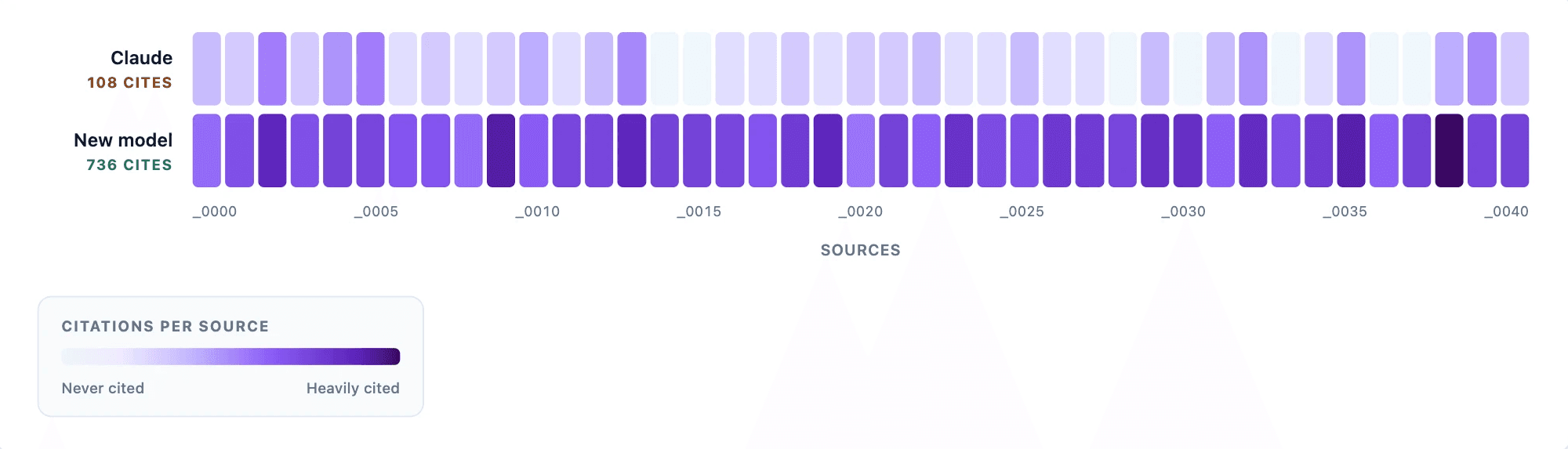
"I've been using it (new Thought Partner Chat) and it is definitely more accurate and less 'fixated' on particular respondents, much much better than the last iteration."
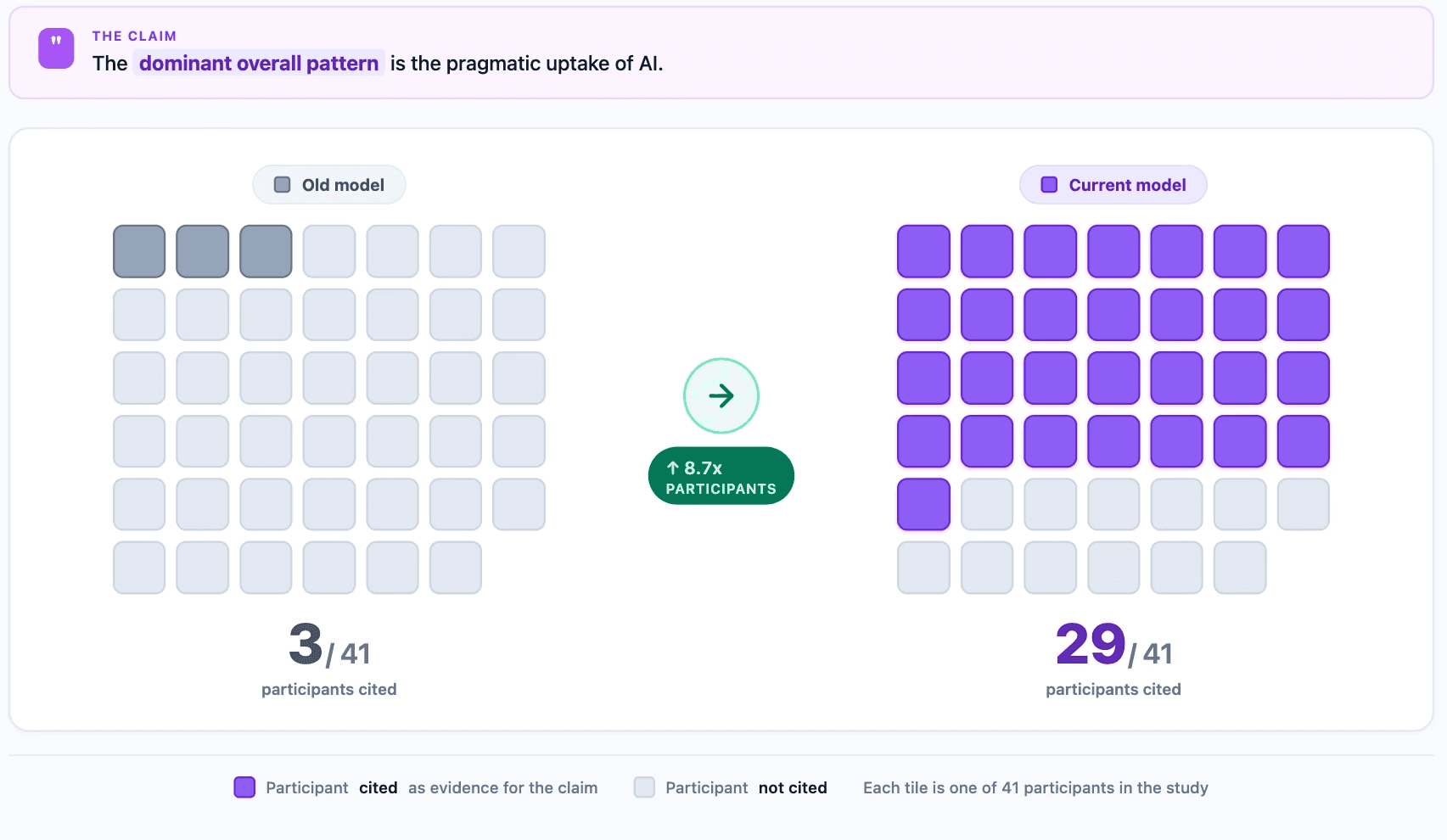
3. Accurate prevalence
When the model says "most," "many," or "a few," the citations behind those words back up the claim, so you no longer get "the majority view" pulled from a handful of participants.
4. Precision and control in analysis
The Thought Partner Chat stays inside the scope you set. When a question implies a comparison across groups or concepts, each one is analysed separately. When a question references a specific part of the discussion guide, analysis stays anchored to that section instead of pulling from across the whole interview. The result reads closer to what you'd find if you ran the analysis by hand.
5. Deeper and more nuanced output
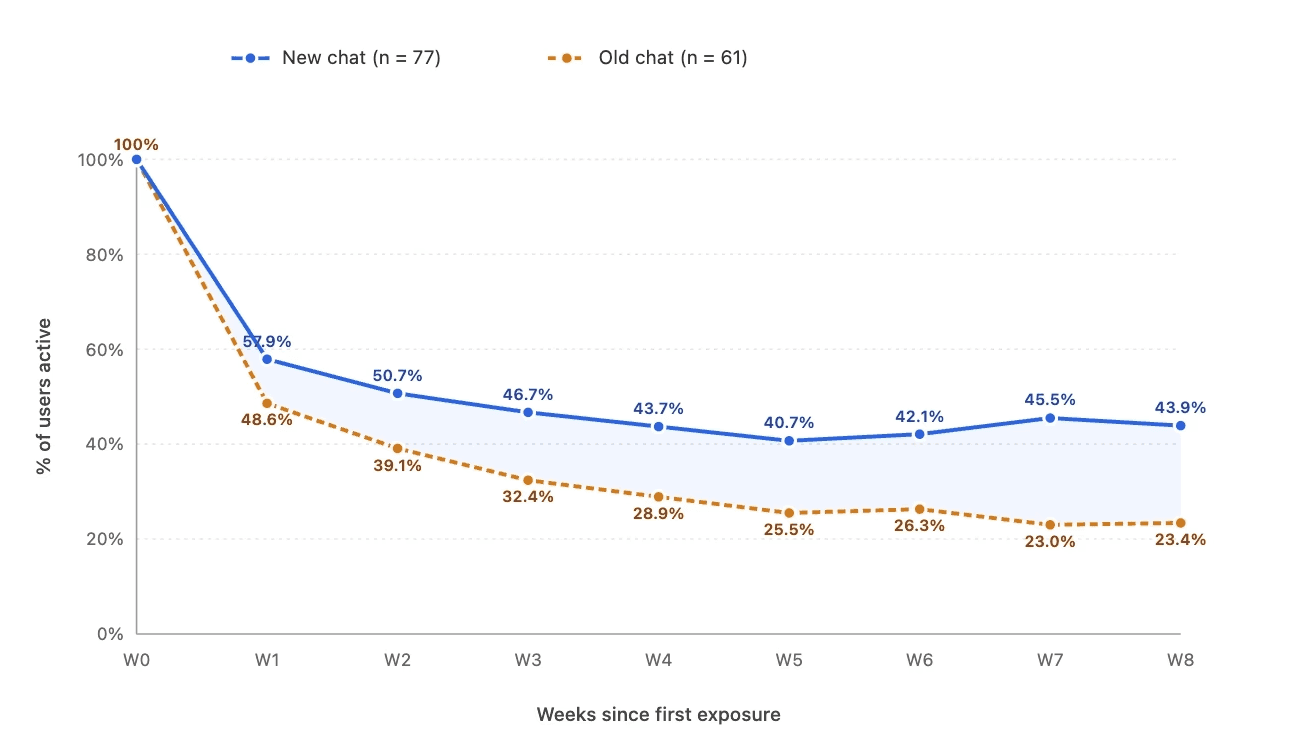
More detail and context are preserved in the analysis, so nuance doesn't get flattened. Since release, 5-star ratings have climbed 1.2x, and 8-week retention is 20% higher than the old chat.
Try it now
The new Thought Partner Chat is live for every CoLoop user. Early users are telling us great things, returning more often, and rating it higher. Open your last project, ask a question you'd normally check by hand, and see the difference.
We're continuing to build. New Analysis Grids will bring a more powerful grid experience for structured work. Research Skills will support workflows for specific methodologies. And expanded file upload is coming to chat, drop in a screenshot for more context, or ask it to validate a deck
Thanks to every researcher who gave us feedback, sat through an interview, or hosted us on-site. The new Thought Partner Chat exists because you told us. We'll keep building the same way, with you.

